
Get started
Welcome to the Mintleaf! Mintleaf is a light weight framework tool helps you to advance your database developement on continuous integration / continuous delivery model as easy as possible.
Features
- Simplified Database Migration
- Compare Data between database tables/csv/spreadsheets/list of objects/any custom data sources
- Data export/import: database table to CSV, CSV to database table and, between database tables
- Unit testing: write automated tests and run them on migrated database schemas, objects, data integrity checks during CI/CD.
- Seamless Test life cycle management such as creation of test data, test data setup, test data teardown, schema and any database objects using changesets
- Extensibility framework offers you the power of customizations - custom data wrappers, custom import/export, custom comparer implementation, and report generation and so on..
- Low memory overhead, high performance on large datasets for data exports, imports, and data compare scenarios
- Nothing more but to use Plain old SQL that you know of
Installation
![]()
<dependency>
<groupId>org.qamatic</groupId>
<artifactId>mintleaf-core</artifactId>
<version>1.8.25</version>
</dependency>
Download binaries
| Command line tools |
| * Windows: mintleaf-cmd-1.8.25-rel.zip |
| * Mac/Linux: mintleaf-cmd-1.8.25-rel.tar.gz |
Quick demo on command line tool
Understanding Mintleaf
Migration at a glance
Database migraton refers to the management of incremental, reversible changes to relational database schemas. A schema migration is performed on a database whenever it is necessary to update or revert that database’s schema to some newer or older version. Look at the below diagram which shows you the schema changes over a period of time during a Agile Software Developement Life Cycle. Every schema changes during a developement sprint will be applied to QA Databases and Prod Database at the end of sprint release.
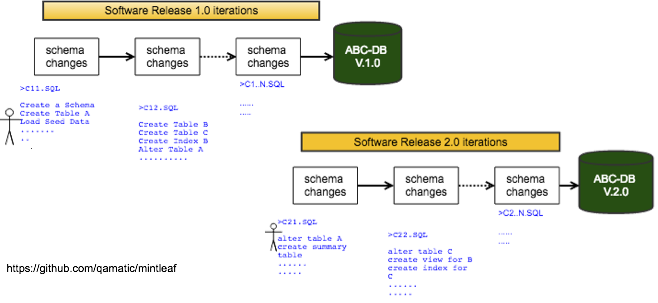
When developing software applications backed by a database, developers typically develop the application source code in tandem with an evolving database schema. The code typically has rigid expectations of what columns, tables and constraints are present in the database schema whenever it needs to interact with one, so only the version of database schema against which the code was developed is considered fully compatible with that version of source code.
Version Control Systems v.s Database Migration Versions?
Teams of software developers usually use version control systems to manage and collaborate on changes made to versions of source code. Different developers can develop on divergent, relatively older or newer branches of the same source code to make changes and additions during development. So version control system by itself does not maintain database versions but data migration tools does it for you. So using Mintleaf you can maintain your database versions either upgrade to a newer version or degrade it a older version.
Why MintLeaf?
Schema migration to a production database is always a risky task. Production databases are usually huge, old, and full of surprise things like the following
- Assumptions on certian data conditions
- Implied dependencies which no body knows
- Unclean / stale data which are hard to resolve
- Direct schema patches for bug fixes
- Direct performance fixes and so on….
So for these reasons, a solid migration process needs high level of discipline through build, test and deploy strategy is a way to go as like shown in below diagram where Mintleaf serves as a tool and as a framework to help an organisation move forward to next level of Agile Database Developement.
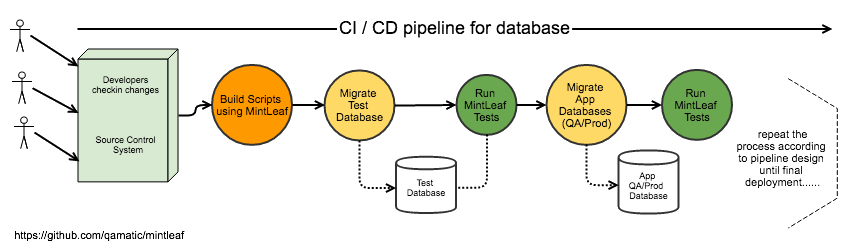
So again, welcome to the Mintleaf! Mintleaf is a light weight framework tool helps you to advance your database developement on continuous integration / continuous delivery model as easy as possible.
Let’s look at the core concepts behind Mintleaf design so that you will be able to understand and use it accordingly before you move onto technical section. Here is the simple steps to get you started quick.
Change-sets
Changesets are basically contains one ore more changes that are to be applied during a database migration. Mintleaf changesets are stored in plain old sql files but changeset information is described using sql comment lines as shown below
-- <ChangeSet id="{a-change-set-id}" delimiter=";" userdata="" />
where,
| Parameter | Description |
|---|---|
| id | The ID of the changeset and it should be unique |
| delimiter | Sql DDL/DML statement delimiter |
| userdata | user defined columns that one can store additional meta data of the changeset. |
For example, a file ‘abcdb-changeset.sql’ contains the following two changesets: create schema and create tables
-- <ChangeSet id="create schema" delimiter=";" userdata="" />
DROP SCHEMA IF EXISTS ABCDB;
CREATE SCHEMA IF NOT EXISTS ABCDB;
-- <ChangeSet id="create tables" delimiter=";" userdata="" />
CREATE TABLE IF NOT EXISTS ABCDB.USERS
(
USERID INT NOT NULL,
USERNAME VARCHAR2(50),
RATE NUMBER(12, 2),
CREATE_TIME DATE DEFAULT sysdate,
CONSTRAINT PK_USERID PRIMARY KEY (USERID)
);
Configuration file
Version profile is a configuration file which contains list of changesets to be applied for a particular version of a database migration. Typically you will have all versions from the beginning to the latest. So the Mintleaf looks for a default version profile at the folder where it is being executed.
dbconfig.xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<mintleaf version="1.0">
<description>Database connections and Schema version configuration file</description>
<databases>
<id>abcdb</id>
<type>ORACLE</type>
<url>jdbc:oracle:thin:your-db-connection-url-here</url>
<username>your-user-name</username>
<password>your-password</password>
<connectionProperties>
<add key="poolsize" value="100"/>
</connectionProperties>
</databases>
<schemaVersions>
<version>
<id>1.0</id>
<changeSets>create schema, load seed data</changeSets>
<scriptLocation>./path/*.sql</scriptLocation>
</version>
</schemaVersions>
</mintleaf>
Components of Mintleaf and tool kits
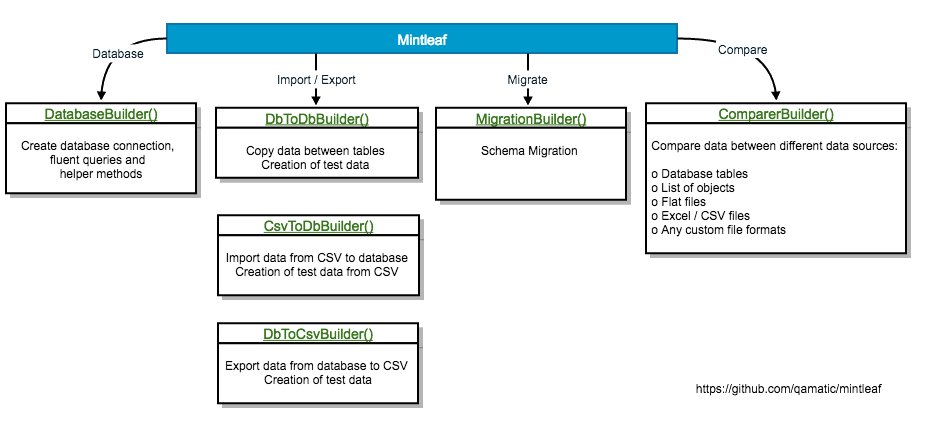
Connection Context & Queries
Connecting to a database
In order to connect to a database, you would need minimum three things - JDBC url, username and a password.
import static org.qamatic.mintleaf.Mintleaf.database;
Database db = new Mintleaf.DatabaseBuilder().
withUrl("< your jdbc url >").
withUsername("user name").
withPassword("password").
build();
Connection Context
Every database connection establishes an exclusive context in which it deals with queries and transactions inside. It is one of the well managed construct in Mintleaf that offers you handle transactions nicely.
Use getNewConnection() method to create a connection context that is required for any database operations either in transactional mode or non-transactional mode.
import static org.qamatic.mintleaf.Mintleaf.database;
//example for user handles connection close()
ConnectionContext connectionContext = h2Database.getNewConnection();
connectionContext.executeSql("INSERT INTO USERS VALUES (1, 'EXAMPLE-USER')");
connectionContext.close() // you must call close here
//example for auto closable
try (ConnectionContext connectionContext = db.getNewConnection()){
connectionContext.executeSql("INSERT INTO USERS VALUES (1, 'EXAMPLE-USER')");
}
This method has an optional parameter for auto close connection. By default, it is set to auto closable but bear in mind that try-resource must be used in order to auto close your connection at the end of the operations otherwise you should call close() method in order to close the connection and release any resources as explained in above example.
executeSql()
Executable<int[]> executeSql(String sql)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
Executable<int[]> executeSql(String sql, Object[] parameterValues)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
| parameterValues | binding Parameter values |
for example,
try (ConnectionContext connectionContext = db.getNewConnection().beginTransaction()){
connectionContext.executeSql("INSERT INTO USERS VALUES (?, ?)", new Object[]{1, "EXAMPLE-USER"});
}
Executable<int[]> executeBatchSqls(List<String> batchSqls)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
| batchSqls | one or more fully formed sqls (without binding parameters) |
executeStoredProc()
Executable<int[]> executeStoredProc(String procedureCall, StoredProcedure.CallType callType,
ParameterBinding.Callable parameterBinding, ExecutionResultListener.Callable executionResultListener)
| Parameter | Description |
|---|---|
| procedureCall | name of the stored procedure |
| callType | PROC, FUNCTION, CUSTOMCALL |
| parameterBinding | binding Parameter values |
| executionResultListener | after execution call back for results |
For example,
try (ConnectionContext ctx = payrollDb.getNewConnection()) {
StoredProcedure proc = new StoredProcedure(ctx, "add_country(?, ?)", StoredProcedure.CallType.PROC, new ParameterBinding.Callable() {
@Override
public void bindParameters(CallableParameterSets parameterSets) throws MintLeafException {
parameterSets.setInt(1, 13);
parameterSets.setString(2, "Lost Country");
}
});
proc.execute();
}
For a stored procedure that returns values
try (ConnectionContext ctx = payrollDb.getNewConnection()) {
Executable proc = ctx.executeStoredProc("{?= call sum_numbers(?,?)}", StoredProcedure.CallType.CUSTOMCALL,
parameterSets -> {
parameterSets.registerOutParameter(1, Types.INTEGER);
parameterSets.setInt(2, 10);
parameterSets.setInt(3, 43);
},
result -> {
System.out.println(result.getInt(1)); //result should 53
});
proc.execute();
}
query() binding
<T> List<T> query(String sql, ParameterBinding parameterBinding, DataRowListener<T> listener)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
| parameterBinding | binding parameters |
| listener | an iterator listener that does call back for every row of a result set |
For example, you want to execute a query with binding parameter values and the result set needs to collected as list of objects / beans
List<String> userNames = connectionContext.query(
"SELECT USERNAME FROM HRDB.USERS WHERE USERID > ? AND USERID < ?", //sql
(parameterSets) -> { // parameter values binding
parameterSets.setInt(1, 77);
parameterSets.setInt(2, 100);
},
(rowNum, resultSet) -> { // iterator listener
return resultSet.asString("USERNAME");
}
);
queryBuilder()
FluentJdbc.Builder queryBuilder()
for example:
Executable<int[]> query = new FluentJdbc.Builder(connectionContext).
withSql(sql).
buildExecute();
query.execute();
Executable<int[]> query = new FluentJdbc.Builder(connectionContext).
withSql(sql).
buildSelect();
SqlResultSet resultSet = query.execute();
Transactional operations
Use beginTransaction() to start a transaction and finally call either commitTransaction() or rollbackTransaction accordingly.
try (ConnectionContext connectionContext = db.getNewConnection().beginTransaction()){
connectionContext.executeSql("INSERT INTO USERS VALUES (1, 'EXAMPLE-USER')");
}
in the above example db.getNewConnection().beginTransaction() in try-resource block will automatically call commitTransaction() otherwise you will have to call it explicitly.
try (ConnectionContext connectionContext = db.getNewConnection().beginTransaction()){
connectionContext.executeSql("INSERT INTO USERS VALUES (1, 'EXAMPLE-USER')");
}
catch (MintLeafException e){
connectionContext.rollbackTransaction();
}
Explicit handling of transaction
ConnectionContext connectionContext = h2Database.getNewConnection();
connectionContext.beginTransaction();
try {
connectionContext.executeSql("INSERT INTO USERS VALUES (1, 'EXAMPLE-USER')");
connectionContext.commitTransaction();
}
catch (MintLeafException e){
connectionContext.rollbackTransaction();
}
finally{
connectionContext.close()
}
Database Select Queries
try (ConnectionContext connectionContext = db.getNewConnection()){
SqlResultSet SqlResultSet = connectionContext.queryBuilder().
withSql("SELECT * FROM USERS").
buildSelect();
}
Standard Queries
Standard queries contains frequently used functions during life cylce of your tests. However you can create your own extensions! see advanced section for detail.
Once you get a connection context then you should be able to use getDbQueries() method to access all standard functions.
try (ConnectionContext connectionContext = db.getNewConnection()){
connectionContext.getDbQueries().<Standard query functions listed below>
}
query()
<T> List<T> query(String sql, DataRowListener<T> listener)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
| listener | an iterator listener that does call back for every row of a result set |
For example, you want to execute a query and the result set needs to collected as list of objects / beans
public class User{
private String userName;
private int rowNumber;
public User(int rowNum,String userName){
this.userName = rowNumber;
this.rowNumber = rowNumber;
}
}
List<User> users = connectionContext.query(
"SELECT USERNAME FROM HRDB.USERS", √
(rowNum, resultSet) -> {
User user = new User(rowNum, resultSet.asString("USERNAME")); // iterator listener
return user;
}
);
// OR something like getting an array list of user names
List<String> userNames = connectionContext.query(
"SELECT USERNAME FROM HRDB.USERS", // sql
(rowNum, resultSet) -> {
return resultSet.asString("USERNAME"); // iterator listener
}
);
query() binding
<T> List<T> query(String sql, ParameterBinding parameterBinding, DataRowListener<T> listener)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
| parameterBinding | binding parameters |
| listener | an iterator listener that does call back for every row of a result set |
For example, you want to execute a query with binding parameter values and the result set needs to collected as list of objects / beans
List<String> userNames = connectionContext.query(
"SELECT USERNAME FROM HRDB.USERS WHERE USERID > ? AND USERID < ?", //sql
(parameterSets) -> { // parameter values binding
parameterSets.setInt(1, 77);
parameterSets.setInt(2, 100);
},
(rowNum, resultSet) -> { // iterator listener
return resultSet.asString("USERNAME");
}
);
queryInt()
This method returns int value of the first column of the first row of a resultSet for the given sql query. Suitable for scalar queries like MAX(), MIN(), AVG(), COUNT() and so on
int queryInt(String sql, ParameterBinding parameterBinding)
| Parameter | Description |
|---|---|
| sql | select query to be executed |
| parameterBinding | binding parameters |
int tableCount = connectionContext.getDbQueries().getInt("SELECT COUNT(*) FROM HRDB.USERS", null);
int tableCountWithRange = connectionContext.getDbQueries().getInt(
"SELECT COUNT(*) FROM HRDB.USERS WHERE USERID > ? AND USERID < ?", //sql
(parameterSets) -> { // parameter values binding
parameterSets.setInt(1, 77);
parameterSets.setInt(2, 100);
}
);
getCount()
int getCount(String tableName)
| Parameter | Description |
|---|---|
| tableName | name of the table |
int count = connectionContext.getDbQueries().getCount("HRDB.USERS");
getMetaData()
ColumnMetaDataCollection getMetaData(String objectName)
| Parameter | Description |
|---|---|
| objectName | get meta data for any sql objects but not limited to table structures alone. You can use it get structure of a view, types etc., |
ColumnMetaDataCollection metaDataCollection = connectionContext.getDbQueries().getMetaData("HRDB.USERS");
getPrimaryKeys()
List<String> getPrimaryKeys(String ownerName, String tableName)
| Parameter | Description |
|---|---|
| ownerName | schema owner name |
| tableName | table name |
// to get list of all available Package bodies
List<String> pkeys = connectionContext.getDbQueries().getPrimaryKeys("HRDB.USERS");
getSqlObjects()
List<String> getSqlObjects(String objectType)
| Parameter | Description |
|---|---|
| objectType | sql objects of a type will be used to filter |
// to get list of all available Package bodies
List<String> list = connectionContext.getDbQueries().getSqlObjects("PACKAGE BODY"); //for oracle database
isColumnExists()
boolean isColumnExists(String tableName, String columnName)
| Parameter | Description |
|---|---|
| tableName | schema name.table name |
| columnName | column name |
// to get list of all available Package bodies
if (connectionContext.getDbQueries().isColumnExists("HRDB.USERS", "USERID") ){
// do something
}
isPrivilegeExists()
boolean isPrivilegeExists(String granteeName, String privilegeName, String objectName)
| Parameter | Description |
|---|---|
| granteeName | user name |
| privilegeName | valid privileges such as SELECT, INSERT and so on |
| objectName | check on objects like TABLE, PROCEDURE, VIEW and so on. |
// to get list of all available Package bodies
if (connectionContext.getDbQueries().isPrivilegeExists("USER1", "SELECT", "HRDB.USERS_IMPORT_TABLE") ){
//do something
}
isSqlObjectExists()
boolean isSqlObjectExists(String objectName, String objectType, boolean ignoreValidity)
| Parameter | Description |
|---|---|
| objectName | a table name / view name / procedure name |
| objectType | a TABLE / PROCEDURE / VIEW / PACKAGE and so on |
| ignoreValidity | look only for valid object/compiled ones if parameter set to false |
// to get list of all available Package bodies
if (connectionContext.getDbQueries().isSqlObjectExists("HRDB.USERS", "TABLE", false) ){
//do something
}
isTableExists()
It returns true/false for a given table exists or not
boolean isTableExists(String tableName)
// to get list of all available Package bodies
if (connectionContext.getDbQueries().isTableExists("HRDB.USERS") ){
// do something
}
isUserExists()
It returns true/false for a given database user exists or not
boolean isUserExists(String userName)
// to get list of all available Package bodies
if (connectionContext.getDbQueries().isUserExists("TINTIN") ){
// do something
}
Creating test data
Before run your test you should load your test data to target test database so that your tests can be run for to prove to be working with developer code changes. So generally, your test scenarios may be involved with one or more database tables that needs to be populated with data in order to verify developer code changes either stored procedure side or application side. Mintleaf simplifies the test data creation process as easy as possible. Here are the possible ways that one can think of creating test data with Mintleaf,
- Create your own data set in a csv file format and load it to your target test database
- Or copy data from existing database to a csv file and later use it for loading in to your target test database
- Or directly copy data from one database to another database/your target test database
So over all you can use csv file and database-to-database copy of data for your tests.
Database to CSV
For example, if we want to dump data from a table called HRDB.USERS in abcd-db to a CSV file then you run like the following
//connect to a database, below is an example for H2 database but you can change to any database
Database h2db = new Mintleaf.DatabaseBuilder().
withUrl("jdbc:h2:file:./target/H2DbTests;mv_store=false;").
build();
//export to csv
Executable action = new Mintleaf.DbToCsvDataTransferBuilder().
withSourceDb(h2db).
withSourceSql("select * from HRDB.USERS").
withTargetCsvFile("users.csv").
build();
action.execute();
CSV to Database
Suppose you have a data in a CSV file called abcd.csv and want to load it in to a table called HRDB.USERS then you run like the following command. Note that CSV file must have a header row as first which contains column names. Please note that whatever the column name you define in CSV file will be used exactly in your targetsql argument as shown below. Here target sql is a template and the CSV column names are prefixed and suffixed with dollar sign as variables. One great thing about using a template approach here is that it enables use of builtin functions of the database inside your insert statement some instances like any date formatting functions or math functions and so on.
//connect to a database, below is an example for H2 database but you can change to any database
Database h2db = new Mintleaf.DatabaseBuilder().
withUrl("jdbc:h2:file:./target/H2DbTests;mv_store=false;").
build();
//import from csv
Executable action = new Mintleaf.CsvToDbDataTransferBuilder().
withSourceCsvFile("users.csv").
withTargetDb(h2db).
withTargetSqlTemplate("UPDATE HRDB.USERS SET USERNAME = '$USERNAME$-changed' WHERE USERID=$USERID$").
build();
action.execute();
Database to Database
Database oracleSourceDb = new Mintleaf.DatabaseBuilder().
withUrl("jdbc:oracle:thin:your-db-connection-url-here").
withUsername("your-user-name").
withPassword("your-Password").
build();
Database h2TargetDb = new Mintleaf.DatabaseBuilder().
withUrl("jdbc:h2:file:./target/H2DbTests;mv_store=false;").
build();
Executable action = new Mintleaf.DbToDbDataTransferBuilder().
withSourceDb(oracleSourceDb). //source db
withSourceSql("SELECT * FROM HRDB.USERS"). // from users table
withTargetDb(h2TargetDb). //target db
withTargetSqlTemplate("INSERT INTO HRDB.USERS_IMPORT_TABLE (USERID, USERNAME) VALUES ($USERID$, '$USERNAME$')").
build();
action.execute();
Supported databases
Oracle
Database oracleDb = new Mintleaf.DatabaseBuilder(DbType.ORACLE).
withUrl("jdbc:oracle:thin:@localhost:1521:xe").
build();
SQL Server
Database oracleDb = new Mintleaf.DatabaseBuilder(DbType.MSSQL).
withUrl("jdbc:sqlserver://localhost:1433/hrdb").
build();
H2
Database h2db = new Mintleaf.DatabaseBuilder().
withUrl("jdbc:h2:file:./target/H2DbTests;mv_store=false;").
build();
MySQL
Database h2db = new Mintleaf.DatabaseBuilder(DbType.MYSQL).
withUrl("jdbc:mysql://localhost:3306/hrdb").
build();
Data compare
With Mintleaf, you can compare two data sets of any kind and it is not just limited to between two database tables. For example one can compare CSV file against a database table or list of objects against a CSV file or against a database table or vice versa. See advanced section as how to implement your own custom comparer implementation.
Comparing two database tables
Database testDb = new Mintleaf.DatabaseBuilder().
withUrl("jdbc:h2:file:./target/H2DbScriptTests;mv_store=false;").
build();
//this db has two tables called USERS and USERS_IMPORTED_TABLE
//tables can come from two different databases too but for this example just one database having two tables compared here
try (ConnectionContext connectionContext = testDb.getNewConnection()) {
SqlResultSet sourceTable = selectQuery(connectionContext, "SELECT * FROM HRDB.USERS");
SqlResultSet targetTable = selectQuery(connectionContext, "SELECT * FROM HRDB.USERS_IMPORT_TABLE");
DataComparer dataComparer = new Mintleaf.DataComparerBuilder().
withSourceTable(sourceList).
withTargetTable(targetListList).
withMatchingResult((sourceColumn, targetColumn) -> {
//here is where you add your compare criteria
if (sourceColumn.equals(targetColumn)){
System.out.println("matches");
}else {
System.out.println(("no match");
}
}).build();
//run data compare
dataComparer.execute();
}
Compare two list of objects
For example you have a POJO class looks like the following.
public class User {
private String firstName;
private String country;
public User(String firstName, String country) {
this.firstName = firstName;
this.country = country;
}
}
We are going two different list of users namely sourceUserList and targetUserList. In order to do compare between sourceUserList and targetUserList, you must implement an interface Row on User class. When you implement Row interface on your bean class, you will have to override getMetaData(), setMetaData() and getValue() methods as shown below. Basically you provide column information as opposed a object properties so this way one can easily deal with nest objects and calculated column values manipulated before returning them. So you can also implement some custom auto inferring mechanism like spring beans via annotations is an idea for those who wants it but its is not the scope here and Mintleaf provides complete freedom to the user as how they would like to implement it.
public class User implements Row { // implement Row interface
private MetaDataCollection metaDataCollection; //add a meta data collection
private String firstName;
private String country;
public User(String firstName, String country) {
this.firstName = firstName;
this.country = country;
}
@Override
public Object getValue(int columnIndex) throws MintLeafException {
switch (columnIndex) {
case 0:
return firstName;
case 1:
return country;
}
return null;
}
@Override
public MetaDataCollection getMetaData() throws MintLeafException {
return this.metaDataCollection;
}
@Override
public void setMetaData(MetaDataCollection metaDataCollection) {
this.metaDataCollection = metaDataCollection;
}
}
now create two different list of Users and populate with some data.
//create a source list of users
List<User> sourceUserList = new ArrayList<User> ();
sourceUserList.add(new User("Tomatoe", "USA"));
//create a target list of users to be compared
List<User> targetUserList = new ArrayList<User> ();
targetUserList.add(new User("Tomatoe", "USA"));
Lets see how compare works between sourceUserList and targetUserList,
// create column metadata
ColumnMetaDataCollection columnDefs = new ColumnMetaDataCollection("USERS");
metaDataCollection.add(new Column("FirstName"));
metaDataCollection.add(new Column("Country"));
//logger
final ConsoleLogger logger = new ConsoleLogger();
//create comparer
DataComparer dataComparer = new Mintleaf.DataComparerBuilder().
withSourceTable(sourceUserList, columnDefs).
withTargetTable(targetUserList, columnDefs).
withMatchingResult((sourceColumn, targetColumn) -> {
//here is where you add your compare criteria
if (sourceColumn.equals(targetColumn)){
logger.info("matches");
}else {
logger.info("no match");
}
//logger.info(String.format("[Source:%s] [Target:%s]", sourceRowState, targetRowState));
}).
build();
//compare now
dataComparer.execute();
Selected Columns
For selected column comparison, use withSelectedColumnMaps()
//logger
final ConsoleLogger logger = new ConsoleLogger();
//create comparer
DataComparer dataComparer = new Mintleaf.DataComparerBuilder().
withSourceTable(sourceUserList).
withTargetTable(targetUserList).
withSelectedColumnMaps("USERNAME=USERNAME,ID=ID").
......
............
. ..................
.build()
Compare with binary files
Binary files are basically accessed in bytes that are encoded in different charset. Mintleaf supports reading these binary files in terms of records. Records basically a set of data which constitues several columns. Mintleaf allows you to define your record structure for your binary files and read them. These records can vary in size and it can be changed at different locations while reading the binary files! So the record size anywhere from 1byte to ‘n’ of bytes which spans across multiple columns.
In order to define a record, you should define its metadata information as follows:
//example record structure,
ColumnMetaDataCollection cityRecordMetaData = new ColumnMetaDataCollection("CITIES") {
{
add(new Column("Id", 4, Types.INTEGER));
add(new Column("City", 16, Types.CHAR));
add(new Column("State", 2, Types.CHAR));
add(new Column("Country", 12, Types.CHAR));
}
};
below code snippets demostrates as how to read a binary file using the above record structure
RowListWrapper<InMemoryRow> list = new ObjectRowListWrapper<>(cityRecordMetaData);
URL url = Thread.currentThread().getContextClassLoader().getClass().getResource("/impexpfiles/cp1047-1.txt");
File file = new File(url.toURI());
try (BinaryReader reader = new RecordFileReader(file, 34)) {
reader.iterate(Charset.forName("Cp1047"), new DataRowListener() {
@Override
public Object eachRow(int rowNum, Row row) throws MintleafException {
list.add((InMemoryRow) row);
return row;
}
@Override
public Row createRowInstance(Object... params) {
return new InMemoryRow(cityRecordMetaData);
}
});
}
User variables
Mintleaf provides you various way to parameterize your sql queries and configuration options apart from the code. Mintleaf uses ANT style variable convention through out the system and the values can from system level or JVM arg level or user supplied properties.
${variable}
To be precise, you could use it inside any sql scripts or dbconfig.xml. For example, a file called h2ddl.sql content would look like the one below and the values of the ${SCHEMA_NAME} would be replaced at run time dynamically.
-- <ChangeSet id="create schema" delimiter=";" />
CREATE TABLE IF NOT EXISTS ${SCHEMA_NAME}.USERS
(
USERID INT NOT NULL,
USERNAME VARCHAR2(50),
CONSTRAINT PK_USERID PRIMARY KEY (USERID)
);
Similary, to have variables inside your configuration files would like below. For example, the database name ${DB_NAME}, ${USER_NAME} and ${PASSWORD} can come from system variables or as part of JVM args
<mintleaf version="1.0">
<description>Database connections and Schema version configuration file</description>
<database>
<id>h2testdb</id>
<type>H2</type>
<url>jdbc:h2:file:./${DB_NAME};mv_store=false;</url>
<username>${USER_NAME}</username>
<password>${PASSWORD}</password>
</database>
</mintleaf>